Heuristic PE String Analysis
2022
The goal behind a heuristic reverse engineering tool is to combat an ever changing range of compilers and packers whose primary purpose is to obfuscate and hide a program’s instructions.
At compile time, high-level languages delegate constructs such as variables, constants, and operators to the compiler and linker, passing them as data objects and instructions placed into different sections of the executable. One of the highest priority elements to inspect during malware analysis are Strings, as they provide immediate insight into program behavior, ranging from UI text to embedded IP addresses, domains, registry keys, and many others.
Why not just use Regex?
Just run a Regex scanner with the query,
\b(HKEY_LOCAL_MACHINE|HKEY_CURRENT_USER|HKEY_CLASSES_ROOT|HKEY_USERS|HKEY_CURRENT_CONFIG)\\([A-Za-z0-9_ .-]+\\?)+
And extract the related strings. But we will look into why this is not the fastest, or even more accurate way. At least not when ran over an entire file.
The first problem: Deciding where Strings reside.
Strings, based on their usage and lifetime, presence of a packer, as well as the compiler, may be stored across multiple sections. For that reason, the first step is to parse and enumerate all available sections and determine whether the executable is packed or protected.
Commonly used sections for String storage include .rdata, .data, and .text. In theory, scanning these sections should be sufficient. In practice, however, malware and protected binaries frequently encrypt Strings, split them across memory, or relocate them into custom or nonstandard sections.As such, all PE headers must be parsed and, preferably, dumped for convenient access. Their respective Relative Virtual Addresses (RVAs) are required for extraction and browsing.
What to scan for:
ASCII Strings in sections deemed relevant to analysis, while prioritizing specific patterns using techniques such as regular expressions. These patterns typically target domains, file paths, registry keys, IP addresses, command-line arguments, and other high priority strings which may have a malicious intent behind them.
For instance, a calculator has no use for external domains and internet access. As such, by extracting the strings in a file, it will be possible to first build a mental understanding of its intent, after which it will be possible to analyze the attached IP addresses and domains for example by Googling or with services like VirusTotal.
VirusTotal Alternatives
Cisco Talos Intelligence, AbuseIPDB and urlscan.
Problem: Noise and irrelevant Strings.
At its core, scanning a file is the act of analyzing raw bytes and attempting to make sense of them. String extraction is effectively the conversion of byte sequences into characters, followed by selecting the sequences that appear useful. Unlike RVAs or structured tables, Strings lack explicit pointers or fixed sizes; the only reliable delimiters for termination.
Generated symbols, compiler metadata, debug data, and misc runtime Strings significantly inflate output and obstruct heuristic analysis. This problem becomes even more pronounced when performing raw extraction, which I will touch on shortly.
A common tewchnique is enforcing a minimum length threshold to reduce junk output. I have also grown fond of entropy calculations which have proven valuable, as they offer insight into whether the data is likely meaningful or simply noise.
In the end, a heuristic scan is intended to guide the analyst toward the most relevant Strings, not to list all of them. However, this approach is imperfect. A strict minimum-length filter may discard short yet important strings such as "cmd", while obfuscation or encoding techniques may split up Strings lessening their relevancy.
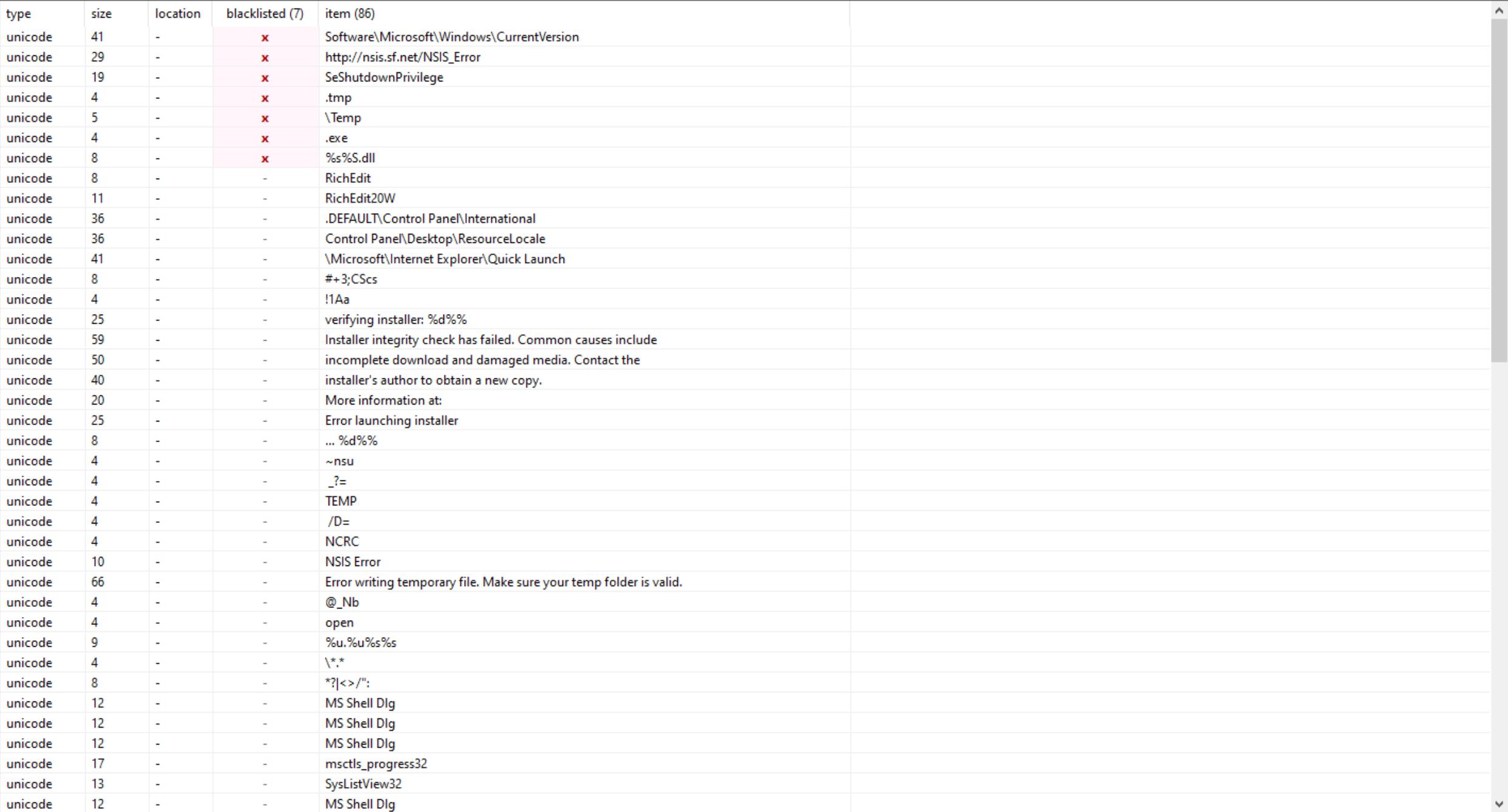
Such techniques are the very basics of obfuscation. Think of a long string such as, "Vastheap.com", being broken up into two distinct strings to lower its visibility and not get picked up by usually found filters. "Vastheap.c" and "om". Then within the code, a simple String.Join() will suffice to circumvent most tools that pick up strings like ExeInfoPE, or PEStudio as seen below.
Example of priortizing strings by highlighting the important ones.
The second problem: Code obfuscation.
As I stated before, a packed binary operates under an entirely different set of assumptions from our perspective when reverse engineering. In the case of a .NET application, for example, the .NET framework is paired with a secondary layer that performs in-memory unpacking while the program is running. This helps prevent relevant data be easily extracted via decompilation, as seen with protectors such as VMProtect and recently with the solution Denuvo. Think of it as an exoskeleton that envelopes the entire application.More conventional packers, such as UPX, compress, rename and pack data and often obfuscate the import table to complicate debugging and navigation.
Static analysis frequently fails because it makes two misplaced assumptions. First, that section schematics are trustworthy. Second, that the packer has not relocated, encrypted, or generated even more junk Strings.
The solution: Raw string extraction.
My philosophy regarding files is simple: they are bytes. Bytes that we convert into hexadecimal and readable strings. Regardless of how sophisticated a packer may be, it inevitably leaves behind traces of its presence and the data it protects. It is important to know the difference between extraction and unpacking. The first is what we are doing here - doing the best with what we have using heuristic scanning. Findings are not always clear, complete or even honest. To achieve that, unpacking and deeper knowledge of the application is required through other means of reverse engineering.Analysis tools often fail because they rely too heavily on structural integrity. When a packer deliberately corrupts or forges structures (DOS Header? They can break even those), traditional approaches break down. Imagine if someone told you to walk down the road and take the first right then you will be at your destination - and when you reach the end of the road, you find out it is a dead end.
This is how static scanning fails: the program extracts an address that appears valid, but the address is fabricated, leading to false data and, in some cases, analyzer crashes.
Raw extraction addresses this issue directly. I developed this approach after encountering repeated crashes caused by unconventional data layouts from not so commonely used compilers, such as Delphi, or when facing entirely different formats that would otherwise require a separate analysis engine, such as Java binaries. As a result, raw extraction became my secondary, yet most reliable, technique for handling unknown or protected file types to help me create a primary opinion.
Another also important distinction is primary analysis and threat mitigation. The first is what we are doing here, trying to assess whether or not the file is safe to run in an otherwise unprotected environment, like your home PC. If it is a protected file for reasons that are not malicious, the goal is not to study its ins and outs but to decide if it is legitimate. Are the IP addresses safe? What does it execute on Shell? And so forth.
Threat mitigation on the other hand includes analyzing a malware to remedy its attack and rollback the damage caused. In that case every bit of knowledge counts, whether it is obfuscated or not.
Back to irrelevant Strings, filtering remains essential. However, raw extraction produces far more data. It may reveal embedded DLLs, import names, export tables, blobs, and so on. Even remenants of the packer. It is not unusual to prioritize labels and trademarks left behind by packers to quickly (not accurately) identify what packer is used. Also important to note that multiple packers can be used on one executable.
Raw byte scanning tolerates an intentionally obfuscated layout, but is limited in the sense that encoded and encrypted data is still not properly extracted. Most basic to intermediate packers I have dealt with however have one fault that this method exploits, and that occurs when they attempt to scramble method or variable names. While it does work when decompiling the code, the packer still has to preserve the original name of the method somewhere, be it for runtime or part of the metadata. The original naming convention is then easily extracted.
A good way to determine whether or not a section is possibly packed is by calculating the Shannon Entropy, a technique I learned to utilize from DiE. In a nutshell, the higher the entropy (>7.3), the more likely the section is packed because then it means the data is more random, which is a main featrure of packers.
Shannon Entropy C#
public static double ShannonEntropy(string s)
{
var map = new Dictionary();
foreach (char c in s)
{
if (!map.ContainsKey(c))
map.Add(c, 1);
else
map[c] += 1;
}
double result = 0.0;
int len = s.Length;
foreach (var item in map)
{
var frequency = (double)item.Value / len;
result -= frequency * (Math.Log(frequency) / Math.Log(2));
}
return result;
}
The third problem: Speed and memory usage.
It is one thing to scan a single section in the file, but scanning the entire file in one go is a different story to load into memory a file dozens of gigabytes in size.The solution: Breaking up the file and calculating density.
Executable files contain vast amounts of irrelevant data: padding, null bytes, metadata (..). By calculating the density of data, it becomes possible to infer the structure of the file and identify regions most likely to contain meaningful information without proper pointers or idea of where the data is stored, like in .UPX(x) sections.The better the implemention, the higher the success and the faster the scan time. Confidence score, entropy calculations and AI accuracy scores help determnine whether or not the string should be extracted and stored or not. That is what it means to privot away from static scanning.
Because as I said above, raw extraction will now be a powerful tool because even if it is not possible to analyze a file the traditional way - like extracting the impor hints and names - you will still be able to extract some of the useful information.